


- Published on
Probability Theory, Maximum Likelihood Estimate & Maximum a Posteriori Estimation
Overview
This is my notes on:
- Lecture 1 Basic of Probability Theory, MSBD5012
- Chapter 1.2 Probability Theory, Pattern Recognition and Machine Learning
- And many other resources ...
Table of Contents
- Sample Space and Event of a Random Experiment
- Probability and Probability Distribution
- Joint Probability
- Marginal Probability
- Conditional Probability
- Independence
- Test of Independence
- Bayes' theorem
- Expectation and Variance
- Likelihood in Machine Learning
- Maximum Likelihood Estimation (MLE)
- Maximum a Posteriori Estimation (MAP)
Sample Space and Event of a Random Experiment
A Random Experiment is a process with uncertain outcomes. A set of all the possible outcomes of the random experiment is called the Sample Space .
- If rolling one dice is the random experiment, the sample space .
A Random Variable is a function that takes a sample space and maps it to a new sample space:
- The easiest one is the identical (1-to-1) function, let the
Random Variablebe the outcomes (the sample space) of rolling one dice (the random experiment). takes values , as well.
A Event is a subset of a sample space :
- describes an
Eventsubset , and it describes we got a value from the random experiment of rolling one dice. - describes an
Eventsubset , and it describes we got a odd number value from the random experiment of rolling one dice.
A Composed Experiment describes the repetitions of the same random experiment, and each repetition can be called a trail.
Probability and Probability Distribution
Let's consider a random variable with discrete outcomes .
denotes the probability of an event of being . For example, if is the smartphone model we found in a random experiment, is the probability of finding an IPhoneSE smartphone in the random experiment.
Taking all outcomes into account, denotes the probability distribution of :
- Probability Mass Function (Histogram) for discrete outcomes.
- Probability Density Function for continuous outcomes.
Joint Probability
Let's say there are two random variables in a random experiment.
- has M outcomes .
- has L outcomes .
Then each observation in the random experiment is a pair of events . denotes the joint probability of two events, and , occurring at the same time.
For example, if and are the smartphone model and the gender we found in an random experiment, respectively, indicates the probability of finding a male with IPhone SE in the random experiment.
After obtaining the joint probability of each pair, we can get the joint probability distribution . To illustrate this idea, the following code generates 1000 pairs (xs and ys):
# Take 1000 samples between [1, 5)
xs = [np.random.randint(1, 5) for _ in range(1000)]
# Take 1000 samples between [1, 3)
ys = [np.random.randint(1, 3) for _ in range(1000)]
# Count the (x, y) pairs and convert them to a dataframe
joint_dist_df = pd.DataFrame.from_dict(Counter(zip(xs, ys)), orient="index").reset_index()
joint_dist_df.columns = ["Event", "P(X, Y)"]
joint_dist_df["X"] = [e[0] for e in joint_dist_df["Event"]]
joint_dist_df["Y"] = [e[1] for e in joint_dist_df["Event"]]
# Compute the joint probability
joint_dist_df["P(X, Y)"] /= joint_dist_df["P(X, Y)"].sum()
joint_dist_df
The above code generates the following dataframe:

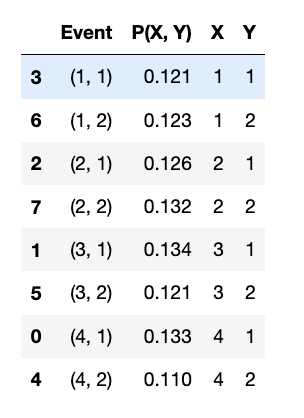
Marginal Probability
Based on the observations above of we can calculate the marginal probability by marginalizing :
For example, if and are the smartphone model and the gender we found in a random experiment, respectively. We can compute by adding up the corresponding joint probabilities for each gender.
Applying this to all 's outcomes we get the marginal probability distribution :
This is called the sum rule of probability theory. The following code shows how to compute the marginal probability distribution:
marginal_x_dist_df = joint_dist_df.groupby("X")["P(X, Y)"].sum().reset_index()
marginal_x_dist_df.columns = ["X", "P(X)"]
marginal_x_dist_df
The above code generates the following dataframe:


Conditional Probability
If we filter the observations by a particular outcome (e.g., ), we can calculate the probabilities of observing given the filtered observations . It is called the conditional probability
The following code shows how to compute the conditional probability distribution :
for x_i in range(1, 5):
print("For x_i =", x_i)
# Filter obseravtions based on x_i
_df = joint_dist_df[joint_dist_df["X"]==x_i].copy()
_df = pd.merge(_df, marginal_x_dist_df, how="left", on="X")
# Calculate the conditional probabilites
_sum = _df["P(X, Y)"].sum()
_df["P(Y|X)"] = _df["P(X, Y)"] / _sum
display(_df)
The above code generates the following dataframe:

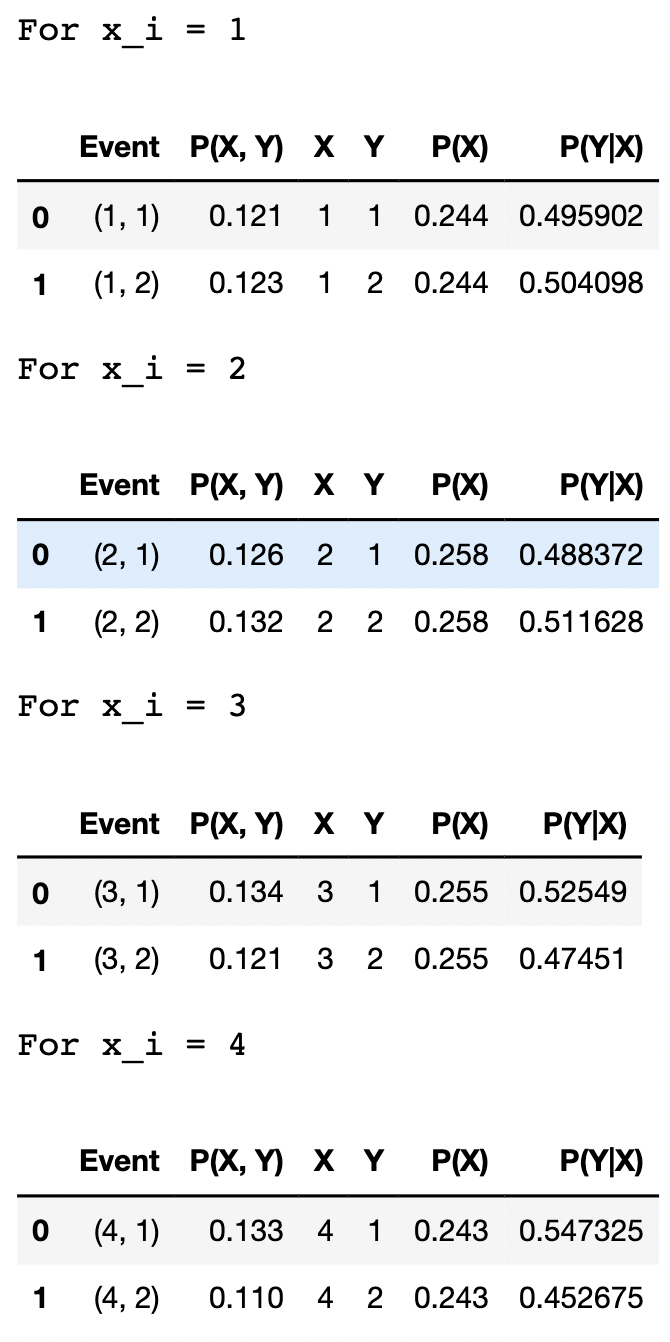
From the result we can also observe that the conditional probability can be calculated with:
And the conditional probability distribution can be written as:
And, is called the product rule of probability theory.
Independence
There is a special case for the product rule above. If two events and are independent, Knowing in advance won't change the probability of having ; therefore:
- The conditional probability becomes
- The conditional probability distribution becomes
Applying this new information to the product rule above we will get:
if and are independent.
Test of Independence
# Take 1000 samples between [1, 5)
xs = [np.random.randint(1, 5) for _ in range(1000)]
# Take 1000 samples between [1, 3)
ys = [np.random.randint(1, 3) for _ in range(1000)]
In the Python coding example, we generated 1000 pairs (xs and ys) uniformly and independently. But why we are not getting a perfect result of ?
Let's find out the reason by looking at the marginal probabilities and . Ideally we should see and from the code output, but it is not the case. Actually, if we increase the sample size, and will get closer to the ideal values.
So there is a problem with counting observations: the probabilities obtained from counting observations are not entirely accurate.
We can also use the Chi-squared test to test if two categorical values are independent. Chi-squared test tests if two categorical variables are dependent on each other or not.
- The null hypothesis: and are independent.
- The alternative hypothesis: and are dependent.
from sklearn.feature_selection import chi2
# The null hypothesis is that they are independent.
# P <= 0.05: Reject the null hypothesis.
# P > 0.05: Accept the null hypothesis.
chi2(np.array(xs).reshape(-1, 1), np.array(ys).reshape(-1, 1))
# > (array([0.88852322]), array([0.34587782]))
The test returns a P-value of 0.346; therefore, we cannot reject the null hypothesis that and are independent.
Bayes' theorem
Recall the product rule , since joint probability distribution is symmetrical , we can deduce the Bayes' theorem like this:
Here,
- describes the probability of finding our target given the
Evidence. It is also called thePosteriorProbability. - describes the probability of finding our target before knowing the
Evidence. It is also called thePriorProbability.
If the new Evidence is value-adding, we should see Posterior deviates from the Prior . In other words, the new Evidence can update our degree of belief.
Also:
This shows the Evidence is for . Therefore, can be understood as the Support of the evidence for our target.
Expectation and Variance
Given a random variable that has outcomes and a probability distribution over different outcomes. The Expectation of over is defined as:
In most cases, we won't know the probability distribution , but we can approximate the Expectation by observations. Let's say we have a dataset with observations that were drawn from the probability distribution with replacement. The Expectation of can be approximated by observations:
The count of obseravtions with over the sample size is the approximate probability .
The Variance of over is defined as:
is the deviation of from its Expectation. The Variance is the Expectation of the squared deviation.
Likelihood in Machine Learning
Let's we have a dataset with observations from a distribution . We want to estimate a model with 2 parameters from a distribution
is the Likelihood of having the parameter given the dataset .
In a training process, we have a varing for a given fixed , therefore the Likelihood is a function of model parameter . For example, given a training dataset and 2 models and , is better if
Also, since is a function of (varying ) in this setting, it is not a probability distribution. is a probability distribution only if it is a function of (varying ).
Maximum Likelihood Estimation (MLE)
There are observations in the dataset :
Assume those samples are independent:
To find the best , we going to maximize the Likelihood:
The objective is also equivalent to maximize the Log-likelihood:
Maximum a Posteriori Estimation (MAP)
In MLE, the Likelihood is a function of (varying ) in this setting, it is not a probability distribution. To have a function of that is a probability distribution given , we need to use the Bayes' theorem to find the Posterior probability of the model parameter is the one we want.
Since is positive, MAP becomes:
The Prior can be considered as the external knowledge of the parameter. MAP is like an external knowledge regularized MLE.
For example, the external knowledge can come from an human expert, then under the MAP setting, a bad model parameter can be avoided by providing a low . An example of bad parameters can be: A model that relies heavily on the gender information for predicting credit default.
When Prior is a uniform distribution, MAP becomes MLE, because it doesn't matter what is, the Prior probability is the same.